I use a burner (temporary) email for filling it at random websites for my testing. Still, I have taken care not to use this email address at unreliable websites.
Somehow, someone got hold of this email address. Now, how can that person check that my address is still valid and active? They need to check this for sending me spam/phishing emails and get a better ROI.
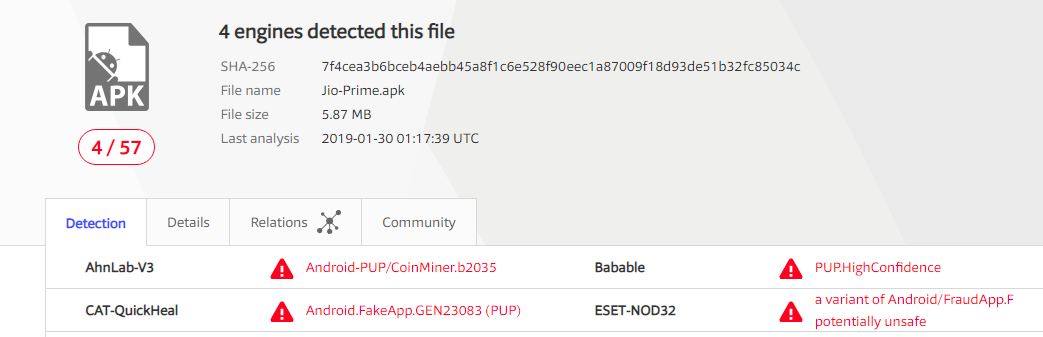
Here’s the technique they used, and I was impressed. Generally I don’t entertain my Spam folder and hence haven’t seen many of such mails. The mail says —

The subject starts with RE: so we think that this might be a reply to our action — Unsubscribe. Also, the subject contains my email address, so we can say that the spammer took efforts to somewhat personalize the mail for each receiver. Everything else is alright in the mail – looks like a valid mail for unsubscribing a service.
At the end, there is this link for unsubscribing from all the mailing lists. I need to click this link for happily unsubscribing. 🙂
Sure, I would do that. But first let me check what’s inside that link. I long press the link to see the full URL —

Errr. This URL is not an URL for unsubscribing from mailing lists. When I click on this, it prompts me to send a mail to all the spammers (their emails listed in screenshot), with mail-body as: “yes my email is lalalalala@gmail.com”.
This way, spammers can verify that my email address is valid and active (since I clicked on their mail). Good thing is, we directly get the list of spammers’ email address. This can be reported to online anti-spam services.
Why is this idea innovative? Many of us randomly subscribe to different mailing lists. After a year or so, we find that the emails are boring or not much relevant/informative. So we find a way to unsubscribe from these mails. And we surely welcome someone who sends us a link for unsubscribing the mails. So there are more chances of us to click on this link.
Why do spammers need to verify our mails? Spammers invest their time and money to compose the spam mails and later harvest some money from the victims. They use mailing services or own email servers for sending spam mails in bulk. If they randomly send 10000 mails and get only 10 replies, this is not much fruitful. Out of these 10000, there are chances that 30-40% of email addresses are inactive now (people stopped using them, typo addresses, forgot password, etc). So the spammers who want to get more replies would first verify whether the email addresses are active or not – because the more active addresses would bring more victims.
Learning from this story is, always check the contents of a hyperlink. Always.







")
")
")